臉書AI研究院近期才開源釋出自家AR技術的核心物件辨識框架Detectron,近日又打造出輕量版的物件偵測和分割架構MaskRCNN2Go,可在行動裝置上即時且準確地偵測人體的動作,MaskRCNN2Go架構是根據臉書自家的物件偵測和分割的架構Mask R-CNN,經過優化和調整後打造出的輕量版本,這套模型現在還在研究階段。
過去,臉書AI相機團隊正在研究多種電腦視覺技術和工具,來協助人們展現自己,舉例來說,透過即時的風格轉換(Style transfer),能夠將使用者的照片或是影片,變成梵谷畫像的風格,搭配及時臉部追蹤器,系統可以幫使用者上妝,甚至將使用者的臉部變成阿凡達,試想,如果能夠將整身都變成阿凡達呢?
為了達到這個任務,臉書AI相機團隊需要正確地即時偵測和追蹤人體的動作,由於要辨識出人的身分和大量的姿勢變動,這是非常具有挑戰性的問題,人體的動作可能是坐著、走路或是跑步,且偵測的對象穿著也不一,可能穿著很長的大衣或是短褲,再加上,偵測的對象可能被其他人或是物品擋住,這些因素都增加創造準確的人體追蹤(Body tracking)系統的困難度。
最近,臉書AI相機團隊開發了能夠準確偵測人體姿勢的新技術,還能區隔人與背景,該套模型只有幾MB,能夠在智慧型手機上即時地偵人體,臉書也表示,將來這套模型可以協助創造更多新的應用,像是用手勢控制遊戲、將人去識別化等。
MaskRCNN2Go的架構
臉書AI相機團隊打造的人體偵測和分割模型,是採用了物件偵測和分割架構Mask R-CNN,Mask R-CNN架構是臉書AI研究院先前發表的論文,還獲得了2017年度國際電腦視覺大會最佳論文獎,Mask R-CNN可以有效地偵測在圖片中的物件,同時預測每個物件外型,建立分割遮罩(Segmentation mask),也就是演算法能夠偵測圖片中每一個物件之後,描繪出每個物件的外型。
為了能夠在智慧型手機上即時執行Mask R-CNN的模型,臉書AI相機團隊、AML和FAIR的研究人員和工程師一同合作,創造了一個高效能且輕量型的架構:Mask R-CNN2Go,Mask R-CNN2Go模型涵蓋了5個元件,分別是主模型、候選區域網路、人體部位偵測器、軀幹偵測器、分割器。
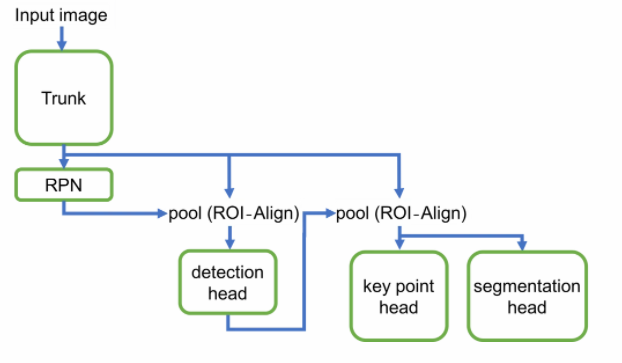
首先,主模型(Trunk model)包含多個卷積層,會產生匯入圖片的特徵,透過候選區域網路(Region Proposal Network)演算法,產生預設大小範圍的候選區域(Bounding box),也就是透過圖片中的邊緣、顏色、紋理等特徵,預先找出圖片中物件可能出現的位置。
接著,區域特徵聚集層(ROI-Align layer)會抽取候選框區域中每個物件的特徵,並傳送到人體部位偵測器(Detection head)。人體部位偵測器包含一系列的卷積層、池化層(Pooling)和全連接層(Fully-connected layers)。
針對每個候選區域,模型會預測該物件與人的相似度,來判定是物件是否為人體,人體部位偵測器也會用非極大值抑制(Non-max suppression)的方法,修正候選區域的座標位置和相鄰的區域,並產生圖片中每個人體的最終候選區域。
有了每個人體的候選區域後,研究團隊在軀幹偵測器(Key point head)中,用另一個區域特徵聚集層,萃取圖片中人體軀幹和頭部特徵,產生人體軀幹的遮罩(Mask),最後,取最大的範圍產生最終的座標位置。
為行動裝置打造的輕量模型MaskRCNN2Go
原本根據影像辨識架構ResNet打造的Mask R-CNN模型,由於受限於行動裝置的運算能力和儲存空間,無法在在手機上執行,為了解決這個問題,臉書為行動裝置開發了高效能的輕量型架構MaskRCNN2Go。
臉書使用了多個方法降低原模型的大小,花了許多時間在優化並修改多個卷積層的寬度,為了確保有足夠大的容納空間,卷積層的核大小臉書採用1×1、3×3和5×5的大小,也修剪權重來減少模型的大小,最終的模型只有幾MB,且非常準確。
為了即時執行深度學習演算法,研究團隊採用並優化臉書的核心架構Caffe2,善用加速神經網路計算的函式庫NNPack、SNPE和 Metal,並將修改過的模型模組化,這樣一來可以打造輕量型的模型,又能確保模型可以快速運行,且避免潛在不相容的問題。
臉書表示,開發行動裝置的電腦視覺模型是個困難的任務,模型在沒有大量的記憶體條件下,必須占用空間小、運算速度快,預測結果還要準確,臉書未來還會持續開發在行動裝置上可執行的高效能模型,來節省所需的電力和運算力。
from iThome 新聞 http://ift.tt/2n975ko

沒有留言:
張貼留言